Im vorangegangenen Blogpost „Football Word Embeddings“ habe ich gezeigt, wie man mit dem Algorithmus Word2Vec ein Korpus von Fußballlivetickern in lexikalischer Perspektive datengeleitet erschließen kann. Jetzt habe ich mit dem großartigen Tensorflow Embeddings Projector eine Möglichkeit entdeckt, das Modell zu visualisieren und – das ist das beste daran – auch für andere zur Verfügung stellen zu können.
Der Tensorflow Embedding Projector hat eine einfach zu bedienende Benutzungsoberfläche und stellt den mit Word2Vec modellierten semantischen Raum auf drei Dimensionen reduziert in einer Art Datenpunktwolke dar. Dazu muss man vorher das Word2Vec-Modell in ein tensorflow taugliches Format bringen, was aber mit diesem built-in-Script sehr einfach geht. Außerdem steht eine Suchfunktion zur Verfügung, um die „most similar words“ zu einem Suchwort ausgeben zu können, die dann sowohl in Listenform als auch in der Wolke angezeigt werden. Die Wolke selbst lässt sich manuell drehen und man kan rein- und rauszoomen. Hier mal ein Eindruck, semantische Äquivalente von „dreschen“, die sich tatsächlich in der Wolke sehr nah beieinander finden:
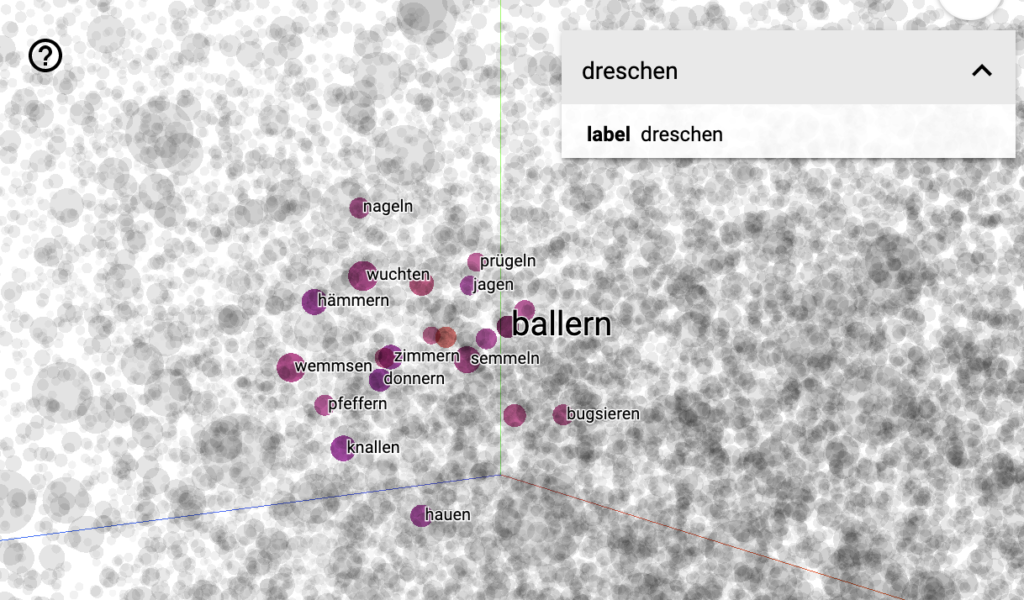
Wenn Ihr das selbst ausprobieren wollt, könnt Ihr die Daten in diesem Repositorium herunterladen (kostenlose Registrierung erforderlich). Nachdem Ihr das Archiv entzippt habt, ruft Ihr den Tensorflow Embedding Projector auf und ladet über den „Load“-Button auf der linken Seite die beiden Dateien hoch. Und das war es auch schon. Jetzt könnt Ihr auf der rechten Seite mal „dreschen“ in das das Search-Feld eingeben und aus den angezeigten Vorschlägen dann tatsächlich auf „dreschen“ klicken. Ihr solltet dann so eine Darstellung wie im obigen Bild sehen.
Der Embedding Projector bietet noch mehr Möglichkeiten, die ich aber selbst noch nicht ganz durchschaue. Dazu später mal mehr.
Schreibe einen Kommentar